Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
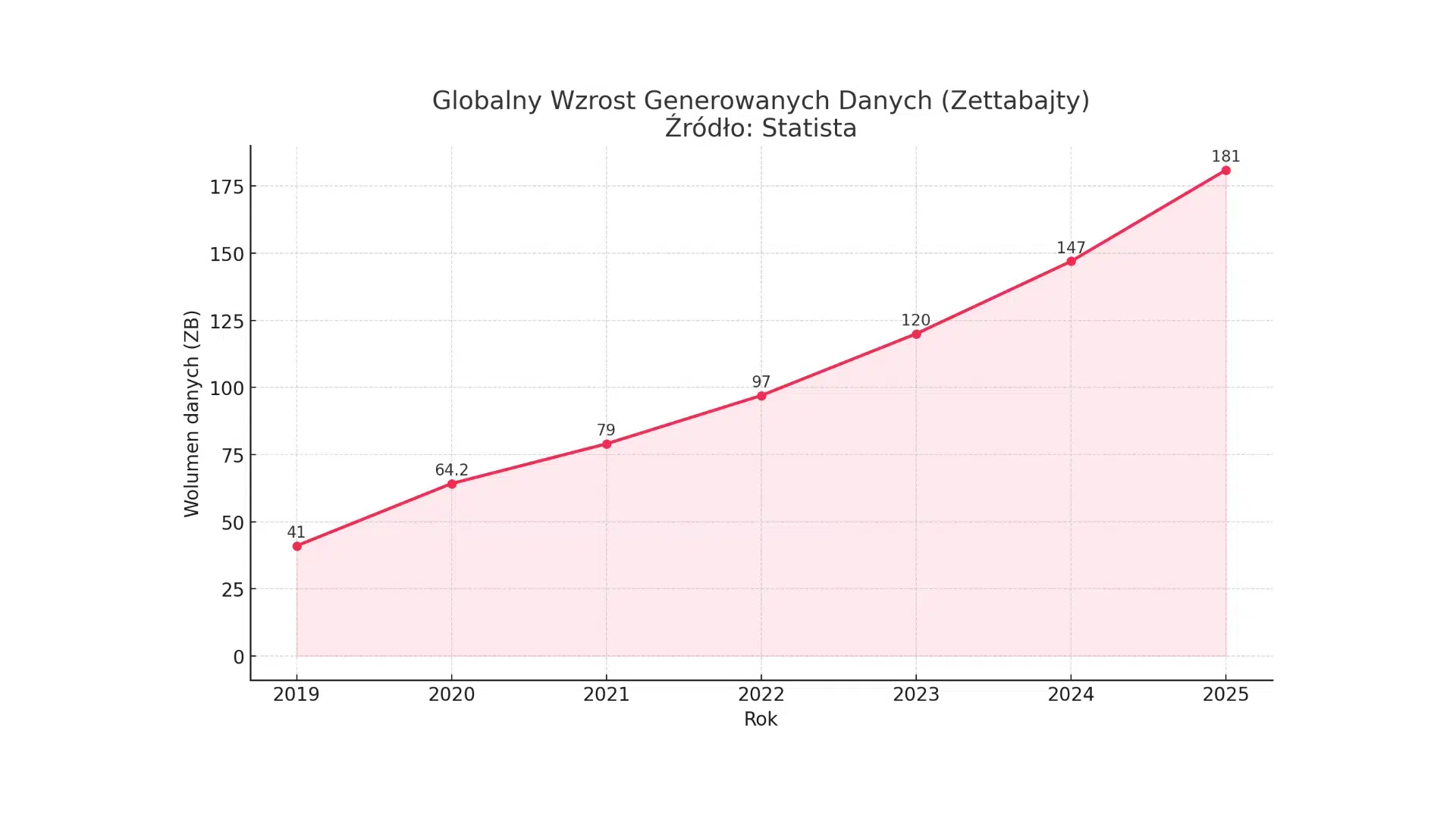
Żyjemy w erze informacyjnej, gdzie dane stały się jednym z najcenniejszych aktywów niemal każdego przedsiębiorstwa. Globalna ilość generowanych, przetwarzanych i przechowywanych danych rośnie w tempie wykładniczym, stawiając przed firmami nowe wyzwania, ale i otwierając bezprecedensowe możliwości. Według prognoz firmy analitycznej IDC, globalna datasfera, czyli suma wszystkich danych cyfrowych, ma osiągnąć od 175 do 200 zettabajtów (ZB) do 2025 roku. Inne analizy, jak te przytaczane przez Statista, wskazują, że tylko w 2025 roku globalnie wygenerowanych zostanie 181 ZB danych. Te astronomiczne liczby nie są jedynie statystyką; obrazują one skalę wyzwania związanego z zarządzaniem, ochroną i wykorzystaniem tego cyfrowego potopu. W Polsce, choć szczegółowe dane dotyczące całkowitego wolumenu danych są trudniejsze do precyzyjnego oszacowania, obserwuje się równie dynamiczny wzrost. Napędzany jest on postępującą cyfryzacją gospodarki, szeroką adopcją nowych technologii, rozwojem handlu elektronicznego oraz rosnącą popularnością usług chmurowych.
Znaczenie dla każdej organizacji, niezależnie od jej wielkości czy branży, nabierają procesy backupu (tworzenia kopii zapasowych) oraz odpowiedniego przechowywania danych (storage). Backup to nie tylko techniczna czynność tworzenia kopii; to fundamentalny element strategii zapewnienia ciągłości działania (Business Continuity) oraz zdolności do odtworzenia systemów i danych po awarii (Disaster Recovery). Utrata kluczowych informacji, czy to w wyniku awarii sprzętu, błędu ludzkiego, cyberataku czy katastrofy naturalnej, może oznaczać dla firmy paraliż operacyjny, dotkliwe straty finansowe, a nawet utratę reputacji i zaufania klientów. Równie istotne jest efektywne i bezpieczne przechowywanie danych. Infrastruktura storage musi być nie tylko wystarczająco pojemna, aby sprostać rosnącym wolumenom, ale także zapewniać odpowiednią wydajność, bezpieczeństwo oraz zgodność z coraz bardziej rygorystycznymi regulacjami prawnymi, takimi jak Ogólne Rozporządzenie o Ochronie Danych (RODO/GDPR), które nakłada na przedsiębiorstwa konkretne obowiązki w zakresie ochrony danych osobowych i zapewnienia ich integralności oraz dostępności.
Zrozumienie złożonej struktury kosztów związanych z backupem i storage, w kontekście nieustannie rosnących wolumenów danych, jest absolutnie kluczowe dla optymalizacji wydatków IT, minimalizacji ryzyka operacyjnego i budowania trwałej, odpornej strategii biznesowej. Nie chodzi już tylko o proste pytanie „ile kosztuje backup?”, ale o głębszą analizę, „jak te koszty są skorelowane z wartością danych, ryzykiem ich utraty oraz ogólną strategią firmy?”. Lawinowy wzrost danych, a zwłaszcza danych o krytycznym znaczeniu dla funkcjonowania przedsiębiorstw – IDC szacuje, że do 2025 roku blisko 20% danych w globalnej datasferze będzie miało status krytycznych dla naszego codziennego życia – przekształca zarządzanie backupem i storage z funkcji czysto technicznej w strategiczny imperatyw biznesowy. Decyzje podejmowane w tym obszarze mają bezpośredni wpływ na odporność firmy na zakłócenia, jej reputację na rynku oraz fundamentalną zdolność do konkurowania i rozwoju. Dane rosną wykładniczo, coraz większa ich część jest niezbędna do działania, a ich utrata prowadzi do poważnych konsekwencji. Dlatego ochrona tych danych (backup) i zapewnienie ich dostępności (storage) stają się elementem strategii zarządzania ryzykiem i ciągłością działania na poziomie zarządczym, a nie tylko zadaniem delegowanym wyłącznie do działu IT.
Co więcej, rosnąca złożoność samych danych – generowanych w czasie rzeczywistym, pochodzących z miliardów urządzeń Internetu Rzeczy (IoT), czy też przetwarzanych przez systemy sztucznej inteligencji (AI) – sprawia, że tradycyjne modele kosztowe oraz dotychczasowe strategie backupu i storage stają się niewystarczające. Dane nie tylko rosną ilościowo, ale zmieniają swój charakter, stając się bardziej dynamiczne, różnorodne i wymagające natychmiastowej reakcji. Tradycyjne metody backupu, często oparte na okresowych kopiach pełnych lub przyrostowych, mogą nie być optymalne dla tak dynamicznych i rozproszonych zbiorów danych. Ta złożoność bezpośrednio wpływa na koszty (np. transferu, przetwarzania, zarządzania) i efektywność systemów. W rezultacie, firmy są zmuszone do ponownej, dogłębnej oceny całkowitego kosztu posiadania (TCO) i aktywnego poszukiwania bardziej elastycznych, skalowalnych i inteligentnych rozwiązań, takich jak usługi chmurowe, platformy Backup-as-a-Service (BaaS) czy narzędzia wykorzystujące mechanizmy sztucznej inteligencji do optymalizacji procesów ochrony danych.
Globalna eksplozja danych to zjawisko bezprecedensowe, którego skala i dynamika są potwierdzane przez liczne raporty firm analitycznych. Zrozumienie tych trendów jest kluczowe dla właściwego planowania strategii backupu i storage.
Globalna eksplozja danych: liczby i prognozy
Według różnych analiz IDC, globalna datasfera, czyli całkowita ilość danych tworzonych, przechwytywanych, kopiowanych i konsumowanych na świecie, ma wzrosnąć z około 45 zettabajtów (ZB) w 2019 roku do wartości szacowanej między 163 ZB a 200 ZB do roku 2025. Statista precyzuje te prognozy, podając, że w 2024 roku globalnie wygenerowanych zostanie 147 ZB danych, a w roku 2025 wolumen ten wzrośnie do 181 ZB. Oznacza to, że każdego dnia na świecie powstaje około 402.74 miliona terabajtów nowych danych. Choć prognozy mogą się nieznacznie różnić w zależności od metodologii i zakresu badania danego raportu, ogólny trend jest jednoznaczny – mamy do czynienia z wykładniczym wzrostem ilości informacji.
Ten imponujący przyrost danych jest napędzany przez kilka kluczowych czynników technologicznych i biznesowych:
Specyfika danych korporacyjnych: nie tylko ilość, ale i struktura oraz wartość
Dane generowane i przetwarzane przez przedsiębiorstwa mają swoją specyfikę. Nie chodzi tu tylko o rosnącą ilość, ale także o zmieniającą się strukturę i zróżnicowaną wartość tych informacji. Tradycyjnie dominujące ustrukturyzowane bazy danych (np. systemy ERP, CRM) stanowią obecnie tylko część zasobów informacyjnych firm. Coraz większy udział mają dane nieustrukturyzowane, takie jak dokumenty tekstowe, wiadomości e-mail, obrazy, pliki wideo, logi systemowe, dane z mediów społecznościowych czy dane telemetryczne z sensorów. Ten typ danych stanowi większość nowo generowanych informacji i wymaga odmiennych podejść zarówno do ich przechowywania (np. z wykorzystaniem skalowalnych systemów Object Storage), jak i do strategii ich backupu.
Kluczowe jest również zrozumienie, że nie wszystkie dane mają jednakową wartość dla organizacji. Od krytycznych danych transakcyjnych, których utrata mogłaby zagrozić istnieniu firmy, przez dane operacyjne niezbędne do codziennej działalności, po dane archiwalne o niskiej częstotliwości dostępu, ale wymagające długoterminowego przechowywania ze względów regulacyjnych lub historycznych. Efektywne zarządzanie kosztami backupu i storage wymaga zatem wdrożenia mechanizmów tieringu danych, czyli klasyfikacji informacji pod względem ich wartości i cyklu życia, a następnie dopasowania strategii ochrony i przechowywania do poszczególnych kategorii.
Polski krajobraz danych: Jak radzą sobie polskie przedsiębiorstwa?
Polski rynek technologii informacyjno-komunikacyjnych (ICT) rozwija się dynamicznie, co bezpośrednio przekłada się na wzrost ilości danych generowanych i zarządzanych przez krajowe przedsiębiorstwa. W 2022 roku całkowita wartość rynku ICT w Polsce wyniosła 24,5 miliarda USD, co oznaczało wzrost o 11,4% w ujęciu dolarowym w stosunku do roku poprzedniego. Sam rynek IT osiągnął wartość 18 miliardów USD, notując wzrost o 14,7%.
Szczególnie dynamiczny rozwój obserwuje się w segmentach związanych bezpośrednio z zarządzaniem danymi. Rynek Data Management w Polsce notuje dwucyfrowe wzrosty, a co istotne, wydatki na rozwiązania chmurowe w tym obszarze już w 2022 roku przewyższyły sprzedaż tradycyjnych licencji on-premise. Potwierdza to globalny trend migracji do chmury. Rynek usług cloud computing w Polsce w 2022 roku był wart 1,3 miliarda USD, co oznaczało imponujący wzrost o 30% w porównaniu do 2021 roku. Prognozy IDC wskazują na dalszy średnioroczny wzrost tego segmentu o około 22,7% aż do 2027 roku, co jest zbliżone do dynamiki obserwowanej na poziomie europejskim.
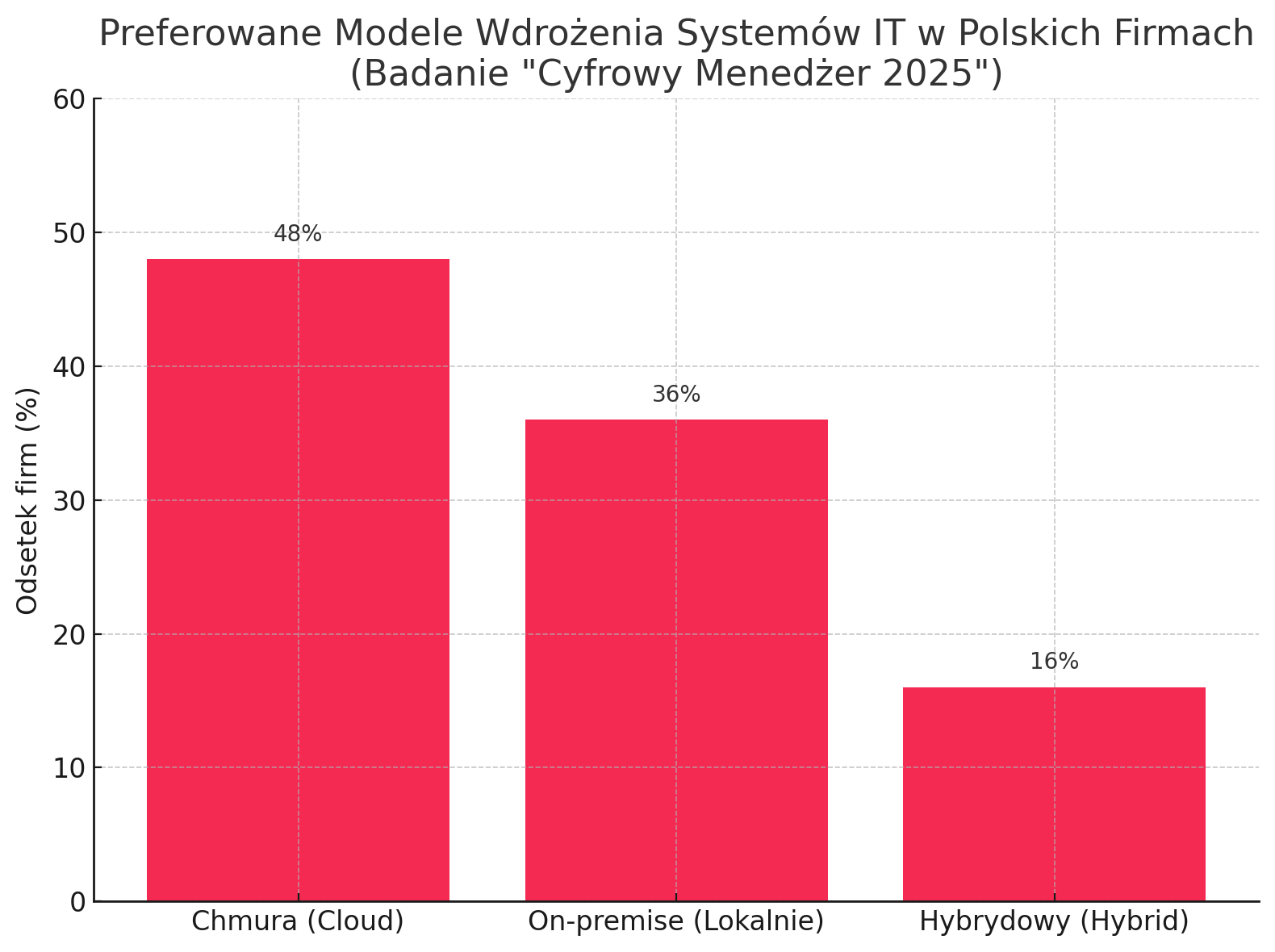
Dodatkowym czynnikiem generującym zapotrzebowanie na rozwiązania IT, w tym backup i storage, jest rosnąca liczba nowych przedsiębiorstw w Polsce, szczególnie w sektorze usług. Polskie firmy coraz częściej dostrzegają korzyści płynące z cyfryzacji i inwestują w nowoczesne technologie. Według danych z raportu „Cyfrowy Menedżer 2025” , aż 48% dostawców systemów IT wskazało chmurę jako najczęściej wybierane rozwiązanie przez ich klientów w 2024 roku. Niemniej jednak, rozwiązania instalowane lokalnie (on-premise) wciąż cieszą się popularnością (36% wskazań), podobnie jak modele hybrydowe, łączące oba podejścia (16%).
Globalny wzrost wolumenu danych jest zjawiskiem bezprecedensowym, jednak regionalne różnice w poziomie adopcji nowoczesnych technologii oraz dostępności zaawansowanej infrastruktury (czego przykładem może być koncentracja największych centrów danych w Stanach Zjednoczonych w porównaniu do Europy czy Polski ) mogą istotnie wpływać na lokalne strategie i koszty związane z backupem i przechowywaniem danych. Polska, mimo dynamicznego rozwoju sektora IT i rosnącej adopcji chmury , wciąż znajduje się na innym etapie rozwoju niż rynki bardziej dojrzałe. Oznacza to, że polskie przedsiębiorstwa mogą kierować się innymi priorytetami, dysponować odmiennymi ograniczeniami budżetowymi, a ich strategie backupu i storage muszą być starannie dostosowane do lokalnej specyfiki, uwzględniając takie czynniki jak dostępność konkretnych usług, obowiązujące regulacje prawne (np. RODO i jego interpretacje) oraz ogólny poziom świadomości technologicznej.
Należy również zwrócić uwagę na rosnący nacisk na przetwarzanie danych w czasie rzeczywistym oraz danych generowanych przez urządzenia IoT. Ten trend wymusza ewolucję nie tylko samych technologii backupu, ale także całej towarzyszącej infrastruktury sieciowej oraz systemów przetwarzania brzegowego (edge computing). Efektywny backup tego typu danych wymaga bowiem nie tylko szybkiej transmisji, ale często także wstępnego przetwarzania informacji blisko źródła ich powstawania. To z kolei generuje nowe, często ukryte lub niebezpośrednio kojarzone z backupem, kategorie kosztów, które muszą być uwzględnione w całościowej analizie TCO. Firmy muszą więc patrzeć na problem ochrony danych szerzej, niż tylko przez pryzmat kosztu samego nośnika czy licencji na oprogramowanie backupowe, uwzględniając cały ekosystem technologiczny niezbędny do efektywnego zabezpieczania i zarządzania tymi nowymi, dynamicznymi typami danych.
Zrozumienie struktury kosztów związanych z backupem i przechowywaniem danych jest fundamentalne dla efektywnego zarządzania budżetem IT. Koszty te są wielowymiarowe i obejmują zarówno wydatki początkowe, jak i długoterminowe koszty operacyjne.
Podstawowe pojęcia – fundament zrozumienia kosztów
Aby precyzyjnie analizować koszty, należy najpierw zdefiniować kluczowe pojęcia:
Główne składniki kosztów – co składa się na rachunek?
Koszty związane z backupem i storage można podzielić na dwie główne kategorie:
Całkowity Koszt Posiadania (TCO) – kompleksowe spojrzenie na wydatki
Aby uzyskać pełny obraz wydatków związanych z systemem backupu i storage, niezbędna jest analiza Całkowitego Kosztu Posiadania (Total Cost of Ownership – TCO). TCO to nie tylko cena zakupu sprzętu czy oprogramowania, ale suma wszystkich kosztów poniesionych przez cały cykl życia danego rozwiązania – od momentu jego nabycia, poprzez wdrożenie, codzienne użytkowanie i utrzymanie, aż po ewentualne wycofanie z eksploatacji. Analiza TCO jest kluczowa przy podejmowaniu strategicznych decyzji, zwłaszcza przy porównywaniu różnych modeli wdrożeniowych, takich jak on-premise, chmura czy rozwiązania hybrydowe. Często okazuje się, że rozwiązanie o niższych kosztach początkowych (np. niektóre usługi chmurowe) może w dłuższej perspektywie generować wyższe koszty operacyjne, podczas gdy inwestycja w infrastrukturę on-premise, choć droższa na starcie, może przynieść oszczędności w kolejnych latach. Na rynku dostępne są narzędzia do kalkulacji TCO, oferowane m.in. przez dostawców takich jak Scale Computing , Druva czy w ramach platformy Azure Migrate. Należy jednak pamiętać, że kalkulatory te często opierają się na pewnych uśrednionych benchmarkach branżowych i zawsze warto krytycznie podejść do wyników, uwzględniając specyfikę własnej organizacji, rzeczywiste ceny rynkowe oraz indywidualne potrzeby.
Porównanie modeli: On-premise vs. Cloud vs. Hybryda
Wybór odpowiedniego modelu wdrożenia systemu backupu i storage ma fundamentalne znaczenie dla kosztów, bezpieczeństwa i elastyczności.
On-premise: Charakteryzuje się zazwyczaj wyższymi kosztami początkowymi (CapEx) związanymi z zakupem sprzętu i oprogramowania. Potencjalnie może oferować niższe koszty operacyjne (OpEx) w długim okresie, pod warunkiem efektywnego zarządzania. Zapewnia pełną kontrolę nad danymi i infrastrukturą, co jest kluczowe dla niektórych organizacji z uwagi na regulacje lub polityki bezpieczeństwa. Wymaga jednak posiadania dedykowanego personelu IT, odpowiedniej przestrzeni oraz ponoszenia kosztów utrzymania i modernizacji infrastruktury.
Cloud: Model chmurowy kusi niskimi kosztami początkowymi i elastycznym modelem subskrypcyjnym (pay-as-you-go), gdzie płaci się za faktycznie wykorzystane zasoby. Oferuje wysoką skalowalność, umożliwiając szybkie dostosowanie pojemności do rosnących potrzeb, oraz odciąża firmę od konieczności zarządzania fizyczną infrastrukturą. Jednak koszty mogą dynamicznie rosnąć wraz ze wzrostem ilości przechowywanych danych i intensywnością ich transferu. Potencjalne wyzwania to także kwestie bezpieczeństwa danych powierzanych stronie trzeciej, ryzyko uzależnienia od jednego dostawcy (vendor lock-in) oraz konieczność zapewnienia zgodności z lokalnymi i międzynarodowymi regulacjami dotyczącymi przechowywania i przetwarzania danych.
Hybryda: Rozwiązania hybrydowe starają się łączyć zalety obu powyższych modeli. Pozwalają na optymalizację kosztów i wydajności poprzez strategiczne umieszczanie różnych typów danych i obciążeń w najbardziej odpowiednich środowiskach (np. krytyczne dane on-premise, mniej wrażliwe dane lub archiwa w chmurze). Model ten oferuje dużą elastyczność, ale jednocześnie może wprowadzać większą złożoność w zarządzaniu całością środowiska IT, wymagając integracji różnych systemów i narzędzi.
Wybór odpowiedniego modelu backupu – czy to on-premise, chmura, czy rozwiązanie hybrydowe – to decyzja wykraczająca daleko poza czysto techniczną czy kosztową analizę. Staje się ona coraz częściej elementem strategicznym, ściśle powiązanym z modelem biznesowym firmy, jej apetytem na ryzyko, specyficznymi wymaganiami regulacyjnymi oraz długoterminowymi planami rozwoju. Przykładowo, dynamicznie rozwijające się startupy, dla których kluczowa jest szybkość działania i elastyczność, mogą naturalnie skłaniać się ku rozwiązaniom chmurowym, oferującym skalowalność na żądanie i minimalne inwestycje początkowe. Z kolei instytucje finansowe, szpitale czy inne podmioty przetwarzające dane szczególnie wrażliwe, mogą kłaść znacznie większy nacisk na pełną kontrolę nad danymi i infrastrukturą, preferując model on-premise lub rozwiązania oparte na chmurze prywatnej, nawet jeśli wiąże się to z wyższymi kosztami początkowymi. Różne modele backupu charakteryzują się odmiennymi profilami kosztowymi i operacyjnymi , a firmy posiadają unikalne potrzeby biznesowe i regulacyjne. Dlatego „optymalny” model jest silnie skorelowany ze strategią i specyfiką danej organizacji, co wykracza poza prostą kalkulację kosztu za gigabajt.
Zależność między lawinowym przyrostem danych a wydatkami na ich ochronę i przechowywanie jest złożona, lecz fundamentalna dla stabilności finansowej i operacyjnej przedsiębiorstw. Zrozumienie tej korelacji, a także potencjalnych konsekwencji zaniedbań, jest kluczowe dla menedżerów IT i decydentów biznesowych.
Bezpośredni wpływ wolumenu danych na wydatki na backup i storage
Najbardziej oczywistą korelacją jest fakt, że im więcej danych generuje i przechowuje firma, tym większe są jej potrzeby w zakresie pojemności systemów storage oraz częstotliwości lub zasobożerności procesów backupu. Bezpośrednio przekłada się to na wzrost kosztów związanych z zakupem lub subskrypcją licencji na oprogramowanie (które często są uzależnione od chronionej pojemności lub liczby maszyn), rozbudową infrastruktury sprzętowej (dyski, macierze, serwery), wynajmem przestrzeni w chmurze oraz transferem danych. Badanie przeprowadzone przez 451 Alliance (obecnie część S&P Global Market Intelligence) wykazało, że całkowita ilość danych zarządzanych przez ankietowane przedsiębiorstwa wzrosła średnio o ponad 20% w ciągu jednego roku, z prognozami jeszcze szybszego wzrostu w kolejnych okresach. Taka dynamika nieuchronnie wywiera silną presję na budżety IT przeznaczone na backup i storage.
Prognozy globalnych i polskich wydatków na IT, ze szczególnym uwzględnieniem ochrony danych
Globalne prognozy wydatków na IT potwierdzają rosnące znaczenie inwestycji w infrastrukturę i oprogramowanie do zarządzania danymi oraz ich ochrony:
Prognozy rynkowe dla specyficznych segmentów ochrony danych są również optymistyczne. Rynek oprogramowania do backupu i odzyskiwania danych ma globalnie wzrosnąć z 14,95 miliarda USD w 2024 roku do 16,66 miliarda USD w 2025 roku (co oznacza średnioroczny wskaźnik wzrostu CAGR na poziomie 11,5%), a do 2029 roku jego wartość ma osiągnąć 29,31 miliarda USD (CAGR 15,2%). Podobnie, rynek systemów enterprise storage ma wzrosnąć ze 146,36 miliarda USD w 2024 roku do 159,11 miliarda USD w 2025 roku (CAGR 8,7%), a do 2029 roku jego wartość ma wynieść 219,29 miliarda USD (CAGR 8,4%). Inny raport, przygotowany przez Market Research Future, prognozuje jeszcze bardziej dynamiczny wzrost rynku Enterprise Data Storage – z 318,24 miliarda USD w 2025 roku do 974,59 miliarda USD w 2034 roku (CAGR 13,24%).
Czy budżety IT nadążają za przyrostem danych? Wyzwanie dla CIOs
Pomimo rosnących inwestycji, kluczowym wyzwaniem dla dyrektorów IT (CIOs) i menedżerów finansowych jest fakt, że wolumen generowanych danych często rośnie szybciej niż dostępne budżety na ich przechowywanie i ochronę. Wspomniane wcześniej badanie 451 Research alarmowało, że budżety na storage on-premise, choć rosnące (średnio o 11% w momencie publikacji badania w 2019 r.), nie nadążają za znacznie szybszym przyrostem danych. Prowadzi to do sytuacji, w której organizacje „nie będą w stanie wykupić się z problemu” jedynie poprzez zwiększanie pojemności. Co więcej, analiza wykazała, że znaczna część wzrostu budżetów na storage jest przeznaczana na utrzymanie istniejącej infrastruktury („keeping the lights on”) lub jej cykliczne odświeżenie, a jedynie mniejsza część (27% według badania) wspiera nowe projekty i innowacje biznesowe. To poważny sygnał ostrzegawczy, wskazujący na ryzyko niedoinwestowania w strategiczne zdolności zarządzania danymi.
Ukryte koszty zaniedbań: cena utraty danych, przestojów, kar RODO
Niedostateczne inwestycje w backup i storage, lub wybór nieefektywnych rozwiązań, niosą ze sobą ryzyko poniesienia znacznie wyższych, często ukrytych kosztów. Są to przede wszystkim koszty związane z utratą danych, przestojami w działalności oraz potencjalnymi karami za nieprzestrzeganie regulacji.
Uświadomienie sobie realnych, finansowych konsekwencji zaniedbań w obszarze ochrony danych jest kluczowe. Tabela ta stanowi mocny argument za tym, że koszt prewencji, czyli inwestycji w solidne rozwiązania backupu i storage, jest zazwyczaj znacznie niższy niż koszt reakcji na incydent i usuwania jego skutków. Decydenci biznesowi często kierują się analizą kosztów i korzyści, a przedstawienie konkretnych, wysokich kosztów potencjalnych strat jest bardziej przekonujące niż ogólne stwierdzenia o „ważności backupu”. Dane pochodzące z renomowanych źródeł, takich jak IBM czy ITIC, dodają tym argumentom wiarygodności i pozwalają szybko zrozumieć skalę ryzyka finansowego, co powinno motywować do proaktywnych działań i uzasadniać wydatki na odpowiednie zabezpieczenia.
Obserwuje się rosnącą dysproporcję między szybkością generowania nowych danych a zdolnością wielu organizacji do ich efektywnego zabezpieczania i zarządzania w ramach często ograniczonych budżetów. Ta sytuacja prowadzi do powstawania swoistego „długu technologicznego” w obszarze ochrony danych. Firmy, odkładając niezbędne inwestycje w modernizację systemów backupu i storage lub wybierając rozwiązania nieadekwatne do skali wyzwań, kumulują ryzyko. Działanie z przestarzałymi lub niewystarczającymi systemami ochrony zwiększa prawdopodobieństwo wystąpienia katastrofalnej utraty danych lub paraliżu operacyjnego w przyszłości. Im dłużej utrzymuje się ten stan, tym większe stają się potencjalne skutki poważnego incydentu, zwłaszcza w obliczu rosnącej liczby i zaawansowania cyberzagrożeń.
Należy również podkreślić, że korelacja między wzrostem wolumenu danych a wydatkami na backup i storage nie jest prostą funkcją liniową. Staje się ona coraz bardziej złożona i wielowymiarowa. Oprócz samego wolumenu, na koszty wpływają takie czynniki jak rosnąca wartość biznesowa danych, coraz bardziej rygorystyczne wymogi regulacyjne (np. RODO), ewoluujące i coraz bardziej wyrafinowane zagrożenia cybernetyczne (szczególnie ransomware) oraz rosnące oczekiwania biznesu dotyczące szybkości odtwarzania danych po awarii (krótkie czasy RTO – Recovery Time Objective i RPO – Recovery Point Objective). Wszystkie te elementy sprawiają, że firmy muszą inwestować nie tylko w więcej przestrzeni dyskowej, ale przede wszystkim w inteligentniejsze, bardziej zautomatyzowane, bezpieczniejsze i wydajniejsze rozwiązania backupowe. Może to prowadzić do skokowego wzrostu wydatków, który jest podyktowany nie tyle samym przyrostem ilości danych, ile raczej ich rosnącą jakością, krytycznością oraz zmieniającym się kontekstem biznesowym i krajobrazem zagrożeń.



